In the complex world of thoroughbred breeding, the quest to produce the next champion has long been guided by a mix of tradition, intuition, and a keen eye for patterns. Breeders and pedigree analysts have honed their skills in recognizing apparent patterns in ancestry, hoping to identify the genetic blueprints for success. However, as the field of data science evolves, it’s becoming increasingly clear that relying solely on traditional methods like nicking and pattern matching across five pedigree generations is not enough to truly understand the intricacies of thoroughbred genetics.
The fundamental challenge lies in distinguishing between meaningful patterns and mere coincidence. As humans, we are naturally drawn to finding patterns and making connections, even when they may not be statistically significant. This tendency, while understandable, can lead us astray in the world of breeding, where countless variables interact in complex ways. Traditional methods often rely on a limited set of data points, making it difficult to account for crucial factors such as sire and dam quality, the produce record of the dam, and the overall strength of the female family.
Description automatically generated with medium confidence”>In recent years, the emergence of big data and advanced analytics has opened up new possibilities for understanding thoroughbred genetics. Companies like Equine Match are at the forefront of this revolution, leveraging vast databases and machine learning algorithms to identify patterns and make predictions that would be impossible through traditional methods alone. By analyzing pedigrees and performance data at an unprecedented scale and depth, these data-driven approaches can control for a wide range of variables and identify the factors that are truly predictive of success.
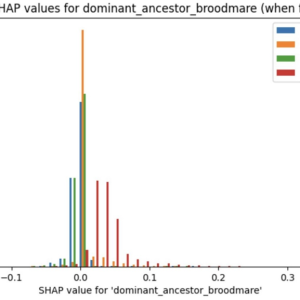
However, it’s important to recognize that even the most sophisticated data analytics cannot eliminate the element of chance in thoroughbred breeding. The complex interplay of genetics, environment, and individual variation means that there will always be a degree of unpredictability in the outcome of any mating. We call that unpredictability aleatoric uncertainty. By focusing on epistemic learning though, we can significantly reduce overall uncertainty in breeding decisions. This approach allows us to account for known knowns and uncover unknown knowns, while also helping to mitigate cognitive biases that can cloud judgment. As we close the gap on epistemic knowledge, we enhance our ability to make more informed and strategic breeding choices. While the unknown unknowns – the true aleatoric uncertainty – will always remain a factor in thoroughbred breeding, the application of rigorous data analysis and continuous learning substantially narrows the scope of unpredictability. This process of epistemic improvement not only reduces uncertainty but also increases the likelihood of breeding success, even in a field where chance will always play a role.
The key, then, is to use data-driven insights to inform and guide our breeding decisions, while remaining humble about our ability to predict the future with certainty. By combining the power of big data with the wisdom of traditional breeding knowledge, we can make more informed choices and tilt the odds in our favor, even if we cannot control every outcome.
As the world of thoroughbred breeding continues to evolve, it’s clear that the future belongs to those who can effectively harness the power of data. Whether through in-house analytics teams or partnerships with specialized firms, breeders who embrace a data-driven approach will be best positioned to navigate the complexities of genetics and produce the champions of tomorrow.
Ultimately, the goal is not to reduce breeding to a simple formula, but rather to use data as a tool to enhance our understanding and inform our decisions. By moving beyond a reliance on apparent patterns and embracing the insights of big data, we can unlock the true potential of the thoroughbred genome and breed smarter.